Fake News Detection with Classical NLP
Supervised text classification of real vs. fake news using TF–IDF features and linear models, with interpretability-focused analysis.
Problem
This project looks at a straightforward but important question: how well can we distinguish between real and fake news articles using text alone? I've been wanting to get into NLP for a while and it seemed particularly relevant to look into fake news detection.
Rather than jumping straight to large neural models, I focused on classical NLP approaches that are fast to train, easy to inspect, and still surprisingly effective. The emphasis here is on understanding what signals the models are actually using, as well as performance.
Dataset
The dataset consists of labeled real and fake news articles. Each article was treated as a standalone document and converted into numerical features using TF–IDF vectorization. This representation captures which words are distinctive within the corpus, while remaining simple enough to reason about directly.
Preprocessing
- Text normalization and tokenization
- Stopword removal
- TF–IDF feature construction
- Train/test split for evaluation
Models
I trained two linear classifiers that are commonly used as strong baselines for text classification tasks: logistic regression and a support vector machine (SVM).
Using linear models keeps the comparison clean: both models operate on the same TF–IDF feature space, making differences in behavior easier to interpret.
Logistic Regression
- Probabilistic linear classifier
- Fast training and stable performance
- Directly interpretable feature weights
Support Vector Machine
- Margin-based classifier
- Well-suited to high-dimensional text data
- Often slightly stronger separation between classes
How the Fake News Detector Behaves
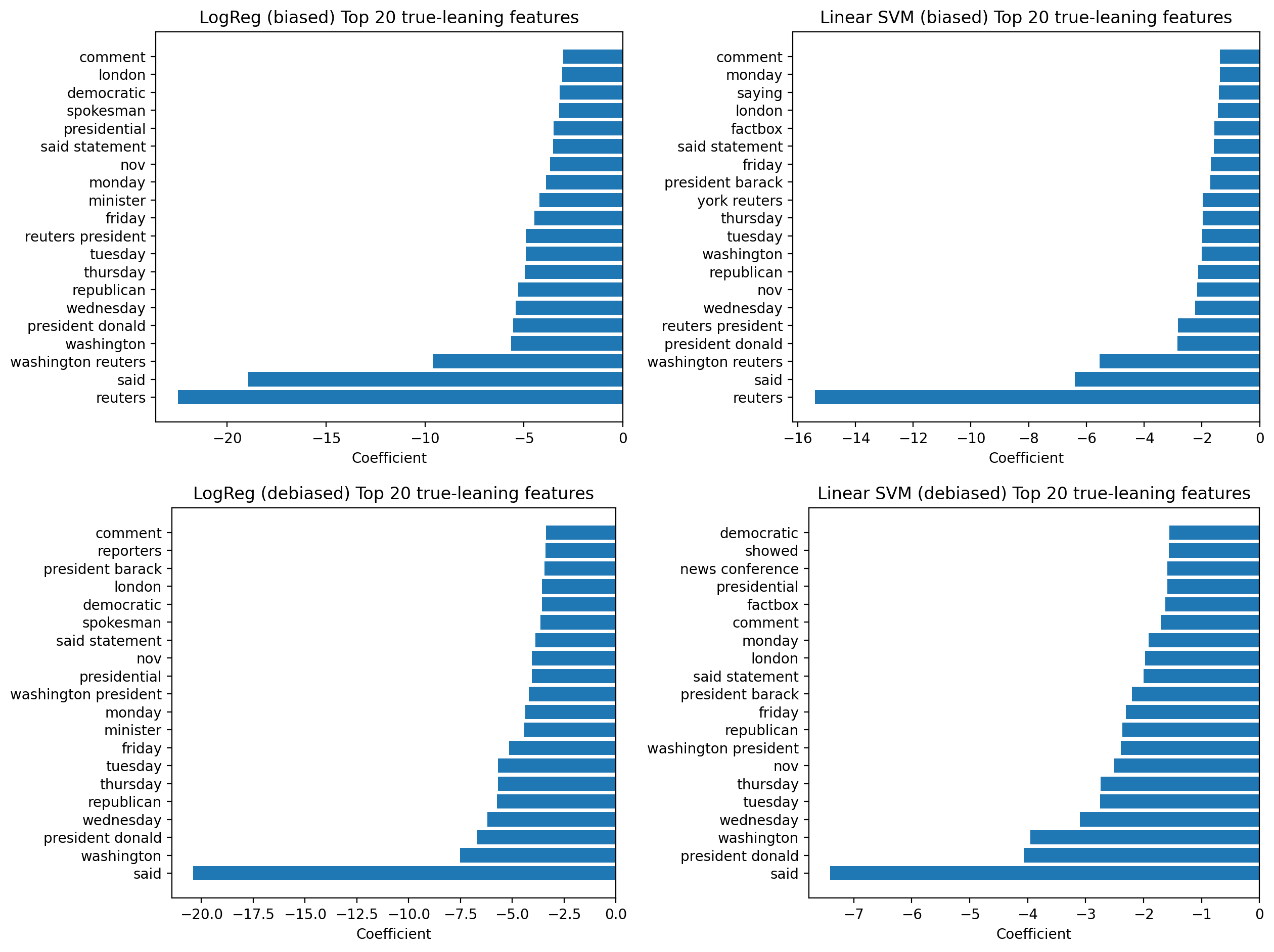
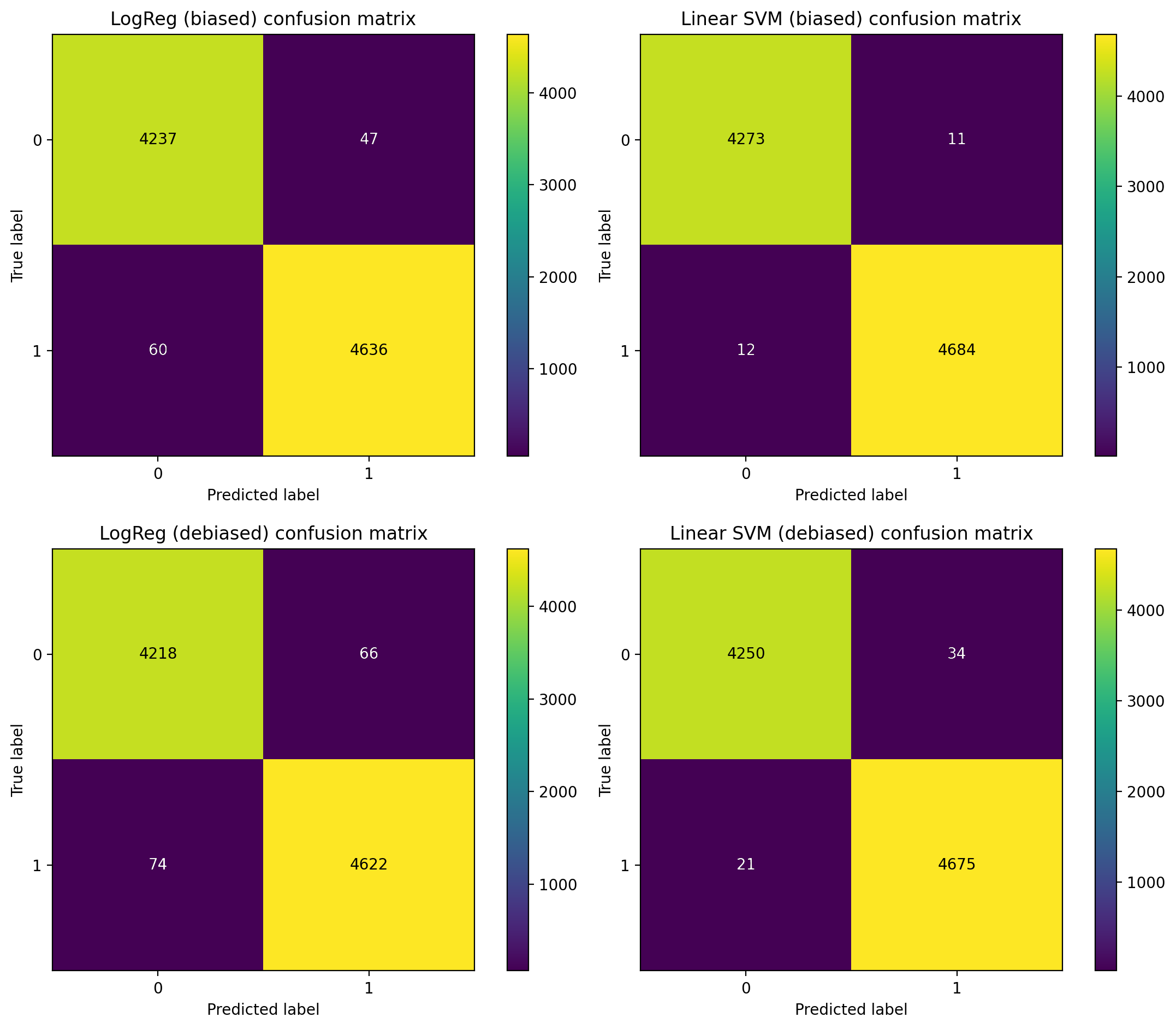
I’m not trying to “wow” anyone with a black box here — the whole point was to build a strong, inspectable baseline. These figures show (1) how often the models get things wrong, (2) what happens when I try to reduce dataset bias, and (3) which words the linear models are actually using as evidence for “fake” vs “real”.
 Click to expand
Click to expand 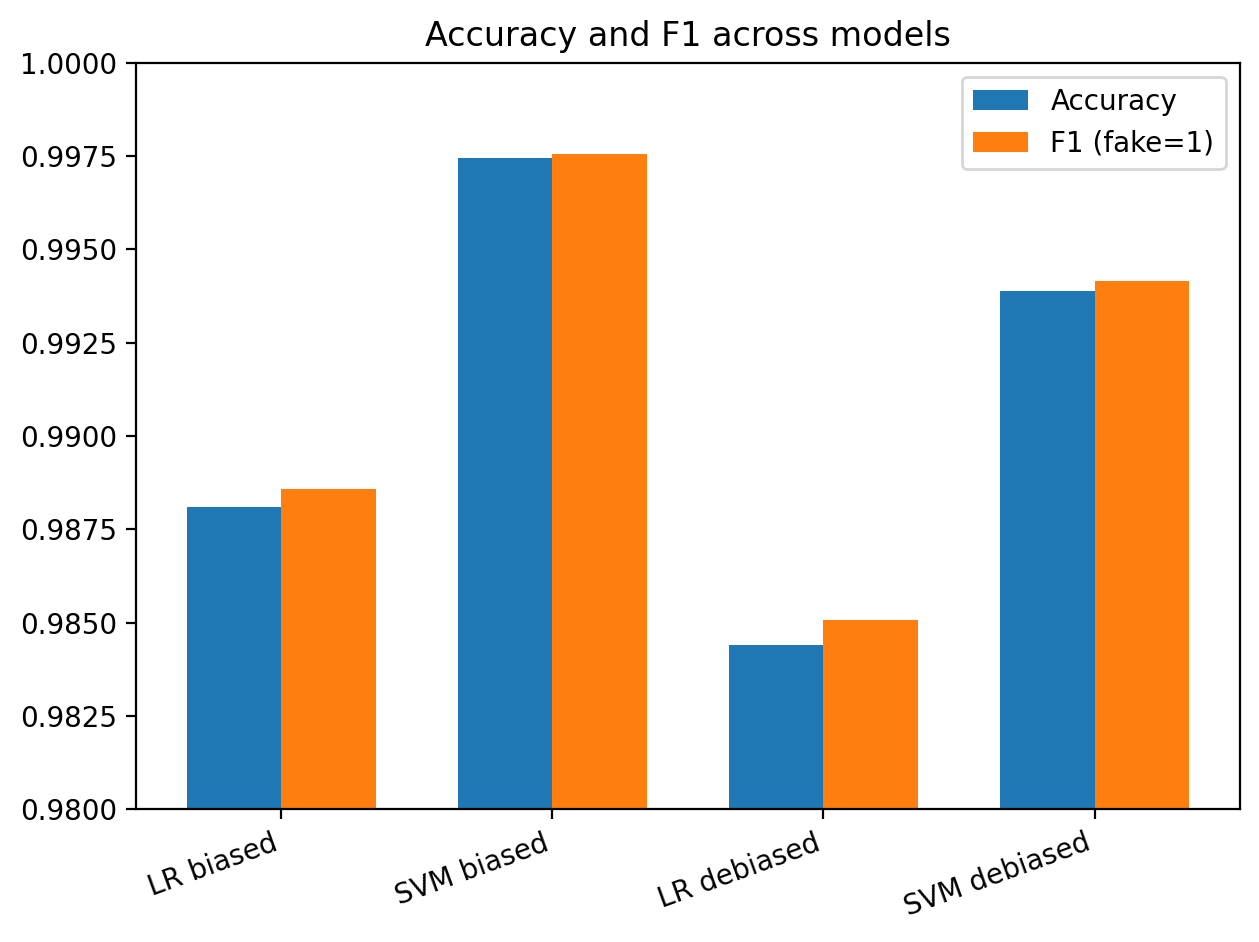 Click to expand Click to expand
Click to expand Click to expand 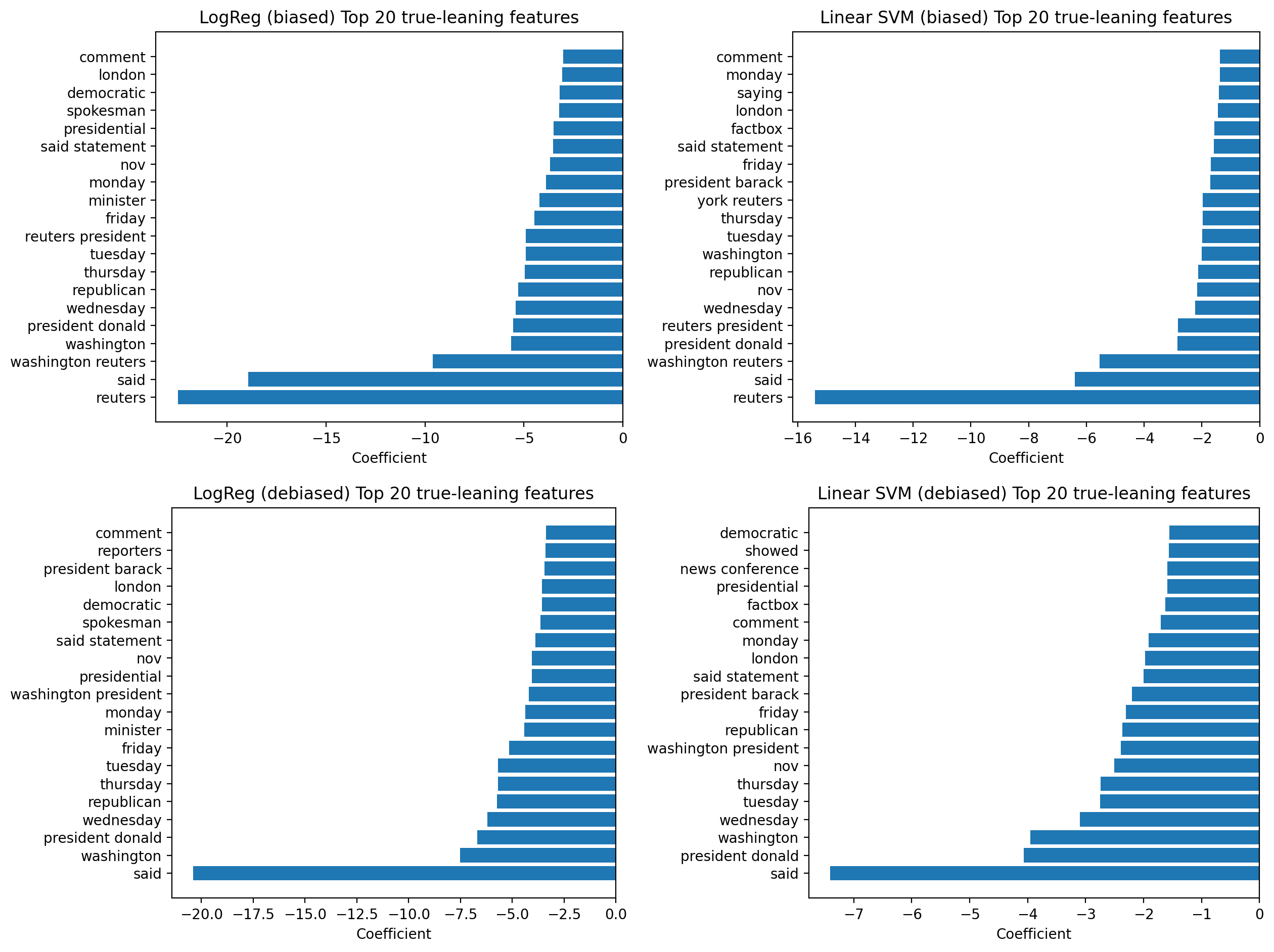 Click to expand
Click to expand Evaluation
Both models achieved strong performance on the test set. The SVM slightly outperformed logistic regression, though the difference was modest.
Rather than focusing only on headline accuracy, I looked closely at the confusion matrices to understand where and how the models failed.
A good next step would also be to write an AI-writing detector, since that is a more prevalent issue.
What I paid attention to
- Balance between false positives and false negatives
- Consistency of predictions across samples
- Qualitative differences in decision boundaries
Interpretability & NLP insight
One advantage of linear models is that their decisions can be inspected directly. By examining feature weights, it’s possible to see which words most strongly influenced the classification.
- Fake news articles tended to rely more on emotionally charged or attention-grabbing language
- Real news articles more often referenced dates, institutions, or named sources
- These patterns align with known stylistic differences in misinformation
While this is a simple NLP pipeline by modern standards, it captures the core idea: transform text into a numerical representation, learn a decision boundary, and interpret what the model has learned.
What this demonstrates
This project shows that classical NLP methods remain strong baselines for text classification, particularly when interpretability matters.
More broadly, it reflects an end-to-end data science workflow: preprocessing raw text, building features, comparing models, evaluating results, and asking what the model is actually doing.